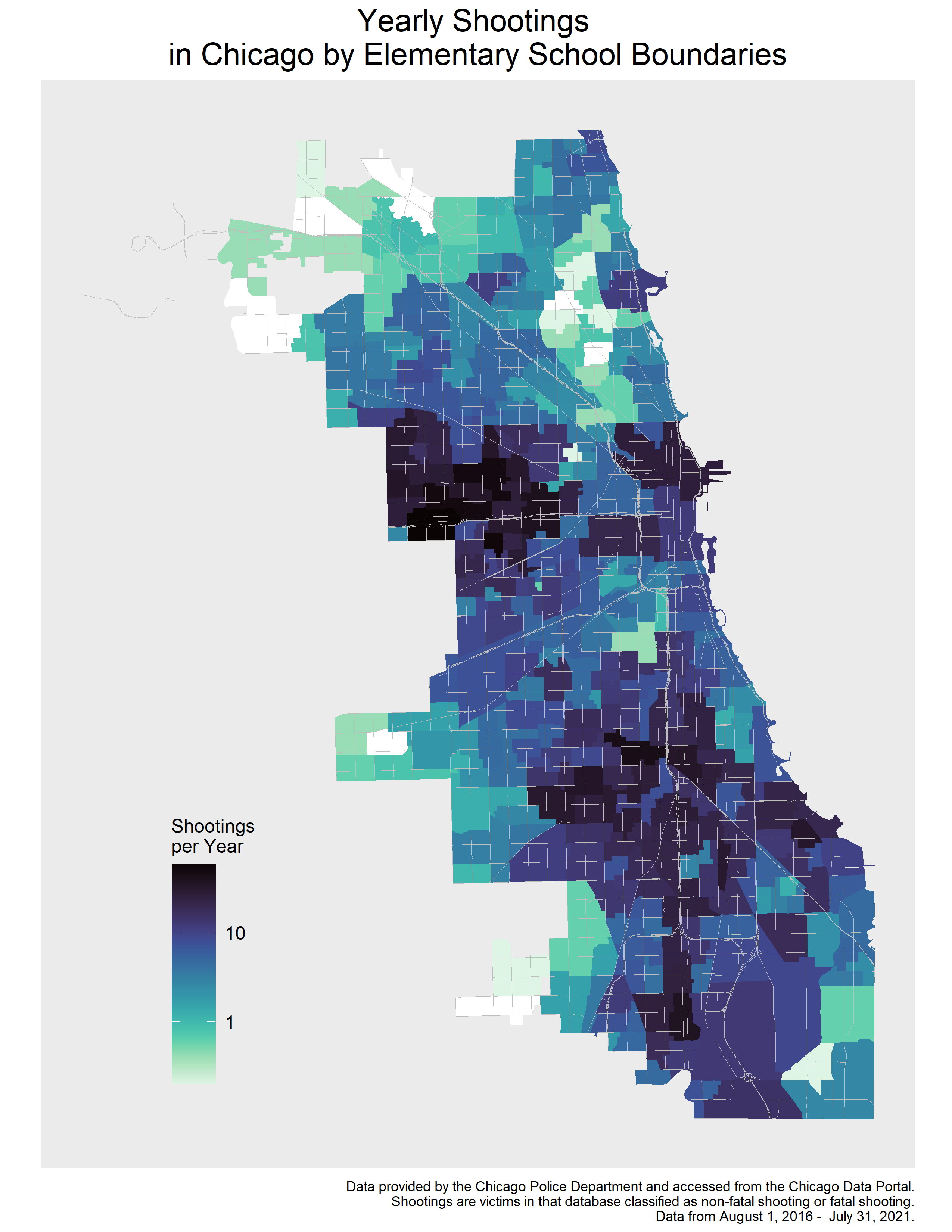
Objective
Scraping data from medium.com and substack.com for subsequent NLP sentiment analysis.
Data Collection
Separate web scraping scripts were written for medium.com and substack.com in Python. Using selenium and XPath, critical elements of article posts, such as headline, description, writer, and date, were extracted.